Now we are going to increase the complexity, instead of the perceptron have a single output, it will have multiple outputs. Multioutput perceptron will allow us to create Classification for the next section.

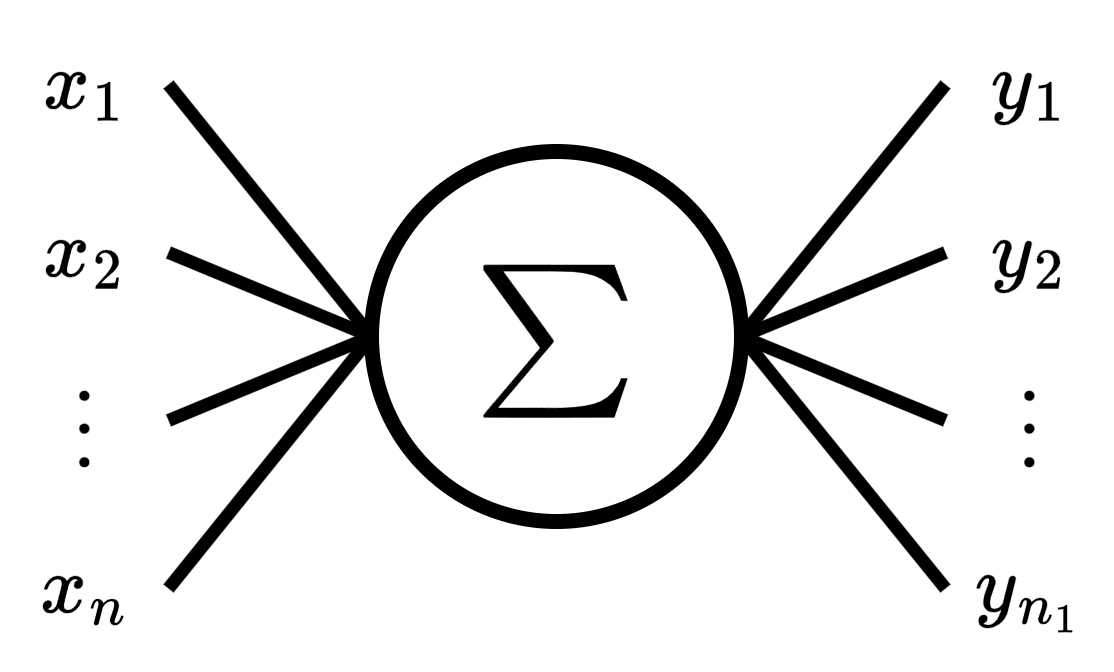
We can think multioutput perceptron as a layer of several multivariate perceptrons, and each perceptron output corresponds to an output feature.
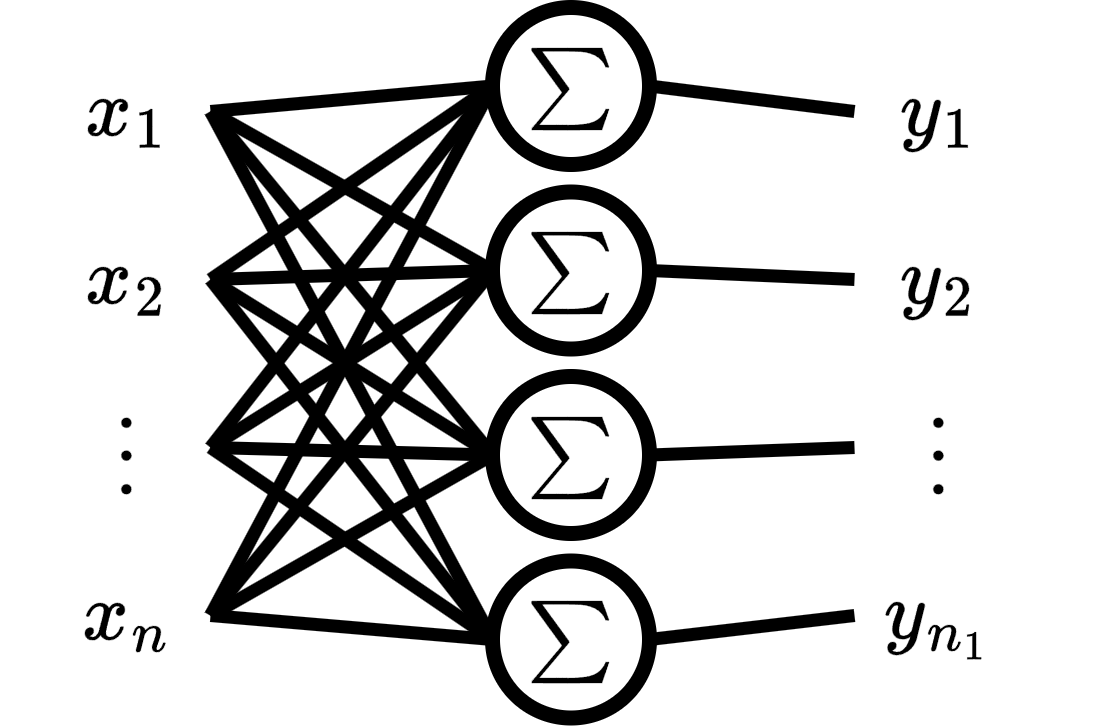
The goal of multioutput perceptron is estimate by a linear approximation such that
Note that the target is now a matrix.
Purpose of this Notebook:
Create a dataset for multioutput linear regression task
Create our own Multioutput Perceptron class from scratch
Calculate the gradient descent from scratch
Train our Perceptron
Compare our Perceptron to the one prebuilt by PyTorch
Setup¶
print('Start package installation...')Start package installation...
%%capture
%pip install torch
%pip install scikit-learnprint('Packages installed successfully!')Packages installed successfully!
import torch
from torch import nn
from platform import python_version
python_version(), torch.__version__('3.12.12', '2.9.0+cu128')device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
device'cpu'torch.set_default_dtype(torch.float64)def add_to_class(Class):
"""Register functions as methods in created class."""
def wrapper(obj): setattr(Class, obj.__name__, obj)
return wrapperDataset¶
create dataset¶
The dataset is consists of the input data and the target data
The input data can be represented as a matrix
where is the number of samples, and is the number of input features.
from sklearn.datasets import make_regression
import random
M: int = 10_100 # number of samples
N: int = 6 # number of input features
NO: int = 3 # number of output features
X, Y = make_regression(
n_samples=M,
n_features=N,
n_targets=NO,
n_informative=N - 1,
bias=random.random(),
noise=1
)
print(X.shape)
print(Y.shape)(10100, 6)
(10100, 3)
split dataset¶
X_train = torch.tensor(X[:100], device=device)
Y_train = torch.tensor(Y[:100], device=device)
X_train.shape, Y_train.shape(torch.Size([100, 6]), torch.Size([100, 3]))X_valid = torch.tensor(X[100:], device=device)
Y_valid = torch.tensor(Y[100:], device=device)
X_valid.shape, Y_valid.shape(torch.Size([10000, 6]), torch.Size([10000, 3]))delete raw dataset¶
del X
del YScratch multiout perceptron¶
weight and bias¶
Our model have two trainable parameters called bias and weight respectively
class MultioutputRegression:
def __init__(self, n_features: int, out_features: int):
self.b = torch.randn(out_features, device=device)
self.w = torch.randn(n_features, out_features, device=device)
def copy_params(self, torch_layer: torch.nn.modules.linear.Linear):
"""
Copy the parameters from a module.linear to this model.
Args:
torch_layer: Pytorch module from which to copy the parameters.
"""
self.b.copy_(torch_layer.bias.detach().clone())
self.w.copy_(torch_layer.weight.T.detach().clone())weighted sum¶
Remark: We cann add a vector to a matrix due to broadcasting mechanism.
@add_to_class(MultioutputRegression)
def predict(self, x: torch.Tensor) -> torch.Tensor:
"""
Predict the output for input x
Args:
x: Input tensor of shape (n_samples, n_features).
Returns:
y_pred: Predicted output tensor of shape (n_samples, out_features).
"""
return torch.matmul(x, self.w) + self.bMSE¶
MSE is now defined as
@add_to_class(MultioutputRegression)
def mse_loss(self, y_true: torch.Tensor, y_pred: torch.Tensor):
"""
MSE loss function between target y_true and y_pred.
Args:
y_true: Target tensor of shape (n_samples, out_features).
y_pred: Predicted tensor of shape (n_samples, out_features).
Returns:
loss: MSE loss between predictions and true values.
"""
return ((y_pred - y_true)**2).mean().item()
@add_to_class(MultioutputRegression)
def evaluate(self, x: torch.Tensor, y_true: torch.Tensor):
"""
Evaluate the model on input x and target y_true using MSE.
Args:
x: Input tensor of shape (n_samples, n_features).
y_true: Target tensor of shape (n_samples, out_features).
Returns:
loss: MSE loss between predictions and true values.
"""
y_pred = self.predict(x)
return self.mse_loss(y_true, y_pred)gradients¶
Let’s follow the same strategy as before:
First, determine the derivatives to be computed
Then, ascertain the shape of each derivative
Finally, compute the derivatives
⭐️ We are using Einstein notation, that implies summation
we will use Einstein notation for chain rule summation, for example
Derivative of MSE respect to bias
and derivative of MSE respect to weight
MSE derivative¶
for , and .
Vectorized form
weighted sum derivative¶
respect to bias¶
for , and
respect to weight¶
for , for , and .
Note: implies summation over the free index .
full chain rule¶
Note: We made the summations explicit for greater clarity for the inner product.
Vectorized form
Note:
is the -th input features of all input samples.
is the -th output feature of all predicted and target data samples respectively.
Vectorized form
final gradient¶
parameters update¶
where is called learning rate.
@add_to_class(MultioutputRegression)
def update(self, x: torch.Tensor, y_true: torch.Tensor,
y_pred: torch.Tensor, lr: float):
"""
Update the model parameters.
Args:
x: Input tensor of shape (n_samples, n_features).
y_true: Target tensor of shape (n_samples, out_features).
y_pred: Predicted output tensor of shape (n_samples, out_features).
lr: Learning rate.
"""
delta = 2 * (y_pred - y_true) / y_true.numel()
self.b -= lr * delta.sum(axis=0)
self.w -= lr * torch.matmul(x.T, delta)gradient descent¶
@add_to_class(MultioutputRegression)
def fit(self, x_train: torch.Tensor, y_train: torch.Tensor,
epochs: int, lr: float, batch_size: int,
x_valid: torch.Tensor, y_valid: torch.Tensor):
"""
Fit the model using gradient descent.
Args:
x_train: Input tensor of shape (n_samples, n_features).
y_train: Target tensor of shape (n_samples, out_features).
epochs: Number of epochs to fit.
lr: learning rate.
batch_size: Int number of batch.
x_valid: Input tensor of shape (n_valid_samples, n_features).
y_valid: Target tensor of shape (n_valid_samples, out_features)
"""
for epoch in range(epochs):
loss = []
for batch in range(0, len(y_train), batch_size):
end_batch = batch + batch_size
y_pred = self.predict(x_train[batch:end_batch])
loss.append(self.mse_loss(
y_train[batch:end_batch],
y_pred
))
self.update(
x_train[batch:end_batch],
y_train[batch:end_batch],
y_pred,
lr
)
loss = round(sum(loss) / len(loss), 4)
loss_v = round(self.evaluate(x_valid, y_valid), 4)
print(f'epoch: {epoch} - MSE: {loss} - MSE_v: {loss_v}')Scratch vs Torch.nn¶
Torch.nn model¶
class TorchLinearRegression(nn.Module):
def __init__(self, n_features, n_out_features):
super(TorchLinearRegression, self).__init__()
self.layer = nn.Linear(n_features, n_out_features, device=device)
self.loss = nn.MSELoss()
def forward(self, x):
return self.layer(x)
def evaluate(self, x, y):
self.eval()
with torch.no_grad():
y_pred = self.forward(x)
return self.loss(y_pred, y).item()
def fit(self, x, y, epochs, lr, batch_size, x_valid, y_valid):
optimizer = torch.optim.SGD(self.parameters(), lr=lr)
for epoch in range(epochs):
loss_t = []
for batch in range(0, len(y), batch_size):
end_batch = batch + batch_size
y_pred = self.forward(x[batch:end_batch])
loss = self.loss(y_pred, y[batch:end_batch])
loss_t.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_t = round(sum(loss_t) / len(loss_t), 4)
loss_v = round(self.evaluate(x_valid, y_valid), 4)
print(f'epoch: {epoch} - MSE: {loss_t} - MSE_v: {loss_v}')torch_model = TorchLinearRegression(N, NO)scratch model¶
model = MultioutputRegression(N, NO)evals¶
We will use a metric to compare our model with the PyTorch model.
import MAPE modified¶
# This cell imports torch_mape
# if you are running this notebook locally
# or from Google Colab.
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
try:
from tools.torch_metrics import torch_mape as mape
print('mape imported locally.')
except ModuleNotFoundError:
import subprocess
repo_url = 'https://raw.githubusercontent.com/PilotLeoYan/inside-deep-learning/main/content/tools/torch_metrics.py'
local_file = 'torch_metrics.py'
subprocess.run(['wget', repo_url, '-O', local_file], check=True)
try:
from torch_metrics import torch_mape as mape # type: ignore
print('mape imported from GitHub.')
except Exception as e:
print(e)mape imported locally.
predictions¶
Let’s compare the predictions of our model and PyTorch’s using modified MAPE.
mape(
model.predict(X_valid),
torch_model.forward(X_valid)
)22.88791240727532They differ considerably because each model has its own parameters initialized randomly and independently of the other model.
copy parameters¶
We copy the values of the PyTorch model parameters to our model.
model.copy_params(torch_model.layer)
parameters = (model.b.clone(), model.w.clone())predictions after copy parameters¶
We measure the difference between the predictions of both models again.
mape(
model.predict(X_valid),
torch_model.forward(X_valid)
)0.0loss¶
mape(
model.evaluate(X_valid, Y_valid),
torch_model.evaluate(X_valid, Y_valid)
)0.0training¶
We are going to train both models using the same hyperparameters’ value. If our model is well designed, then starting from the same parameters it should arrive at the same parameters’ values as the PyTorch model after training.
LR: float = 0.01 # learning rate
EPOCHS: int = 16 # number of epochs
BATCH: int = len(X_train) // 3 # batch sizetorch_model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH,
X_valid, Y_valid
)epoch: 0 - MSE: 15202.6208 - MSE_v: 18460.5819
epoch: 1 - MSE: 14456.9148 - MSE_v: 17699.6765
epoch: 2 - MSE: 13761.3257 - MSE_v: 16975.3579
epoch: 3 - MSE: 13110.6882 - MSE_v: 16285.2623
epoch: 4 - MSE: 12500.5685 - MSE_v: 15627.259
epoch: 5 - MSE: 11927.145 - MSE_v: 14999.4183
epoch: 6 - MSE: 11387.11 - MSE_v: 14399.9842
epoch: 7 - MSE: 10877.5873 - MSE_v: 13827.3522
epoch: 8 - MSE: 10396.0639 - MSE_v: 13280.0497
epoch: 9 - MSE: 9940.334 - MSE_v: 12756.7203
epoch: 10 - MSE: 9508.4513 - MSE_v: 12256.11
epoch: 11 - MSE: 9098.6904 - MSE_v: 11777.0554
epoch: 12 - MSE: 8709.5135 - MSE_v: 11318.4742
epoch: 13 - MSE: 8339.5437 - MSE_v: 10879.3564
epoch: 14 - MSE: 7987.542 - MSE_v: 10458.7572
epoch: 15 - MSE: 7652.3883 - MSE_v: 10055.7907
model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH,
X_valid, Y_valid
)epoch: 0 - MSE: 15202.6208 - MSE_v: 18460.5819
epoch: 1 - MSE: 14456.9148 - MSE_v: 17699.6765
epoch: 2 - MSE: 13761.3257 - MSE_v: 16975.3579
epoch: 3 - MSE: 13110.6882 - MSE_v: 16285.2623
epoch: 4 - MSE: 12500.5685 - MSE_v: 15627.259
epoch: 5 - MSE: 11927.145 - MSE_v: 14999.4183
epoch: 6 - MSE: 11387.11 - MSE_v: 14399.9842
epoch: 7 - MSE: 10877.5873 - MSE_v: 13827.3522
epoch: 8 - MSE: 10396.0639 - MSE_v: 13280.0497
epoch: 9 - MSE: 9940.334 - MSE_v: 12756.7203
epoch: 10 - MSE: 9508.4513 - MSE_v: 12256.11
epoch: 11 - MSE: 9098.6904 - MSE_v: 11777.0554
epoch: 12 - MSE: 8709.5135 - MSE_v: 11318.4742
epoch: 13 - MSE: 8339.5437 - MSE_v: 10879.3564
epoch: 14 - MSE: 7987.542 - MSE_v: 10458.7572
epoch: 15 - MSE: 7652.3883 - MSE_v: 10055.7907
predictions after training¶
mape(
model.predict(X_valid),
torch_model.forward(X_valid)
)6.023391963615669e-16bias¶
We directly measure the difference between the bias values of both models.
mape(
model.b.clone(),
torch_model.layer.bias.detach()
)2.3068030920040977e-16weight¶
mape(
model.w.clone(),
torch_model.layer.weight.detach().T
)1.199589170858017e-16All right, our implementation is correct respect to PyTorch. We have finished this section.
Compute gradients with einsum¶
This implementation is similar, but only changed parameters update with einsum. We will show how to compute the chain rule using explicit Einstein notation.
Remark: is outer product.
The derivative of weighted sum respect to bias is compute as
b_der = torch.einsum(
'p,qr->pqr',
torch.ones(m), # the tensor of 1
torch.eye(no) # kronecker delta
) # result is a tensor of order 3The derivative of weighted sum respect to weight no changes
and it is compute as
w_der = torch.einsum(
'pr,qs->pqrs',
x,
torch.eye(no)
) # result is a tensor of order 4To compute the chain rule
torch.einsum('pq,pqr->r', delta, b_der)torch.einsum('pq,pqrs->rs', delta, w_der)class EinsumLinearRegression(MultioutputRegression):
def update(self, x: torch.Tensor, y_true: torch.Tensor,
y_pred: torch.Tensor, lr: float):
"""
Update the model parameters.
Args:
x: Input tensor of shape (n_samples, n_features).
y_true: Target tensor of shape (n_samples, n_features).
y_pred: Predicted output tensor of shape (n_samples, n_features).
lr: Learning rate.
"""
m, no = y_true.shape
# d L / d Y_pred
delta = 2 * (y_pred - y_true) / y_true.numel()
# d L / d b
b_der = torch.einsum(
'p,qr->pqr',
torch.ones(m, device=device), # the tensor of 1
torch.eye(no, device=device))
self.b -= lr * torch.einsum('pq,pqr->r', delta, b_der)
# d L / d W
w_der = torch.einsum('pr,qs->pqrs', x, torch.eye(no, device=device))
self.w -= lr * torch.einsum('pq,pqrs->rs', delta, w_der)einsum_model = EinsumLinearRegression(N, NO)
einsum_model.b.copy_(parameters[0])
einsum_model.w.copy_(parameters[1])tensor([[ 0.4003, -0.1125, -0.2734],
[-0.0249, -0.3901, 0.3011],
[-0.0633, -0.0902, 0.1784],
[ 0.2862, -0.0737, -0.2647],
[ 0.1376, -0.2813, 0.0322],
[-0.0995, -0.3533, -0.0366]])einsum_model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH,
X_valid, Y_valid
)epoch: 0 - MSE: 15202.6208 - MSE_v: 18460.5819
epoch: 1 - MSE: 14456.9148 - MSE_v: 17699.6765
epoch: 2 - MSE: 13761.3257 - MSE_v: 16975.3579
epoch: 3 - MSE: 13110.6882 - MSE_v: 16285.2623
epoch: 4 - MSE: 12500.5685 - MSE_v: 15627.259
epoch: 5 - MSE: 11927.145 - MSE_v: 14999.4183
epoch: 6 - MSE: 11387.11 - MSE_v: 14399.9842
epoch: 7 - MSE: 10877.5873 - MSE_v: 13827.3522
epoch: 8 - MSE: 10396.0639 - MSE_v: 13280.0497
epoch: 9 - MSE: 9940.334 - MSE_v: 12756.7203
epoch: 10 - MSE: 9508.4513 - MSE_v: 12256.11
epoch: 11 - MSE: 9098.6904 - MSE_v: 11777.0554
epoch: 12 - MSE: 8709.5135 - MSE_v: 11318.4742
epoch: 13 - MSE: 8339.5437 - MSE_v: 10879.3564
epoch: 14 - MSE: 7987.542 - MSE_v: 10458.7572
epoch: 15 - MSE: 7652.3883 - MSE_v: 10055.7907
mape(
einsum_model.w.clone(),
torch_model.layer.weight.detach().T
)1.199589170858017e-16mape(
einsum_model.b.clone(),
torch_model.layer.bias.detach()
)3.4964897774944853e-16