In the notebook 3-1-mlp, we made a single dense layer that contained its own activation function, so it is easy to explain backpropagation. But usually, the Dense layer and the Activation function layer are separated. In this notebook, we separate the Dense layer and the Activation function layer.
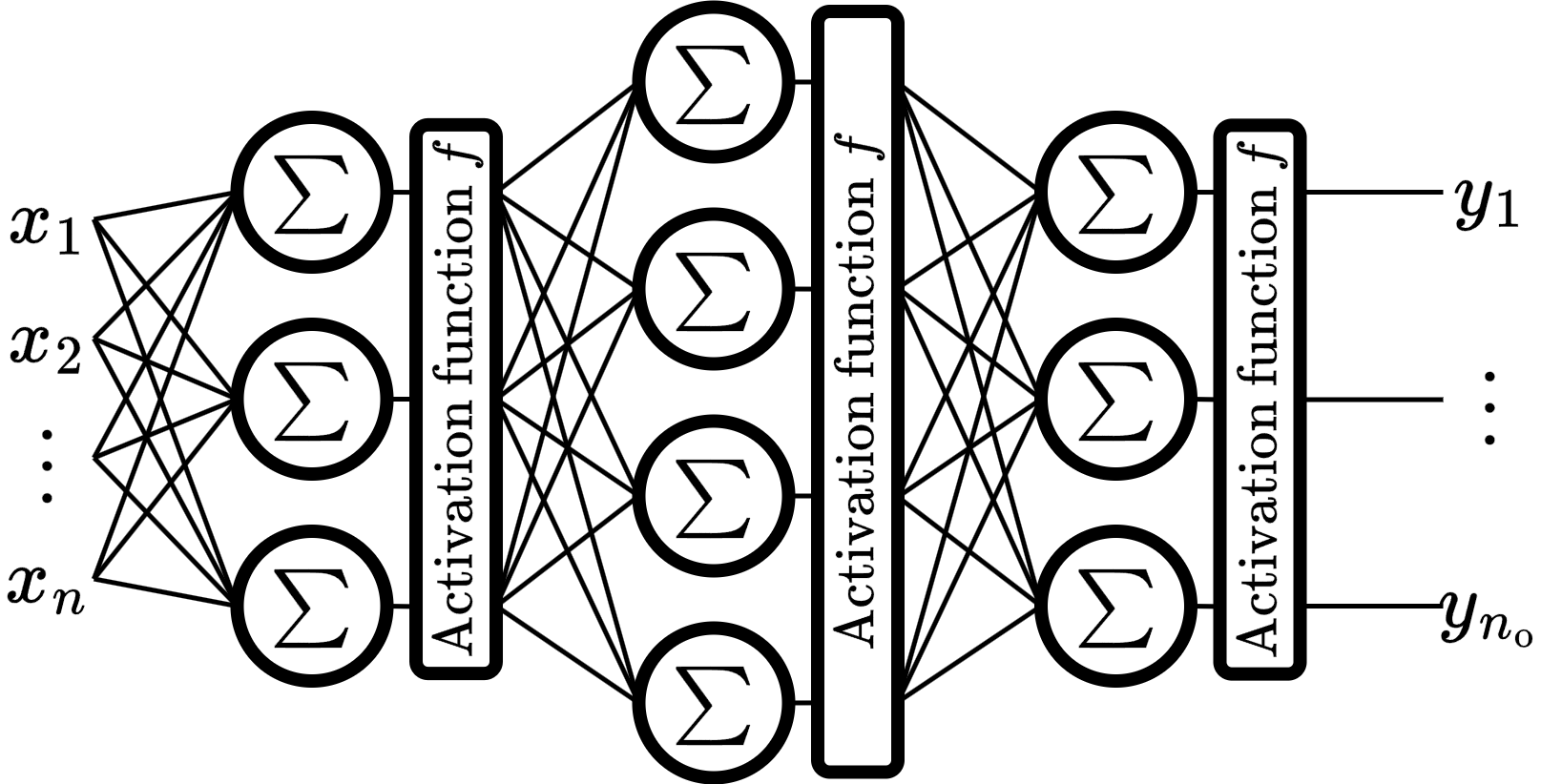
In this notebook we are not going to explain mathematics because, in essence, it is the same thing.
import torch
from torch import nn
from platform import python_version
python_version(), torch.__version__('3.12.12', '2.9.0+cu128')device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
device'cpu'torch.set_default_dtype(torch.float64)def add_to_class(Class):
"""Register functions as methods in created class."""
def wrapper(obj):
setattr(Class, obj.__name__, obj)
return wrapperDataset¶
create dataset¶
from sklearn.datasets import make_classification
M: int = 10_100 # number of samples
N: int = 5 # number of input features
CLASSES: int = 3 # number of output classes
X, Y = make_classification(
n_samples=M,
n_features=N,
n_classes=CLASSES,
n_informative=N - 1,
n_redundant=0
)
print(X.shape)
print(Y.shape)(10100, 5)
(10100,)
one hot encoding¶
Y_hat = nn.functional.one_hot(
torch.tensor(Y, device=device).long(),
CLASSES
).type(torch.float32)
Y_hat.shapetorch.Size([10100, 3])split dataset into train and valid¶
X_train = torch.tensor(X[:100], device=device)
X_valid = torch.tensor(X[100:], device=device)
X_train.shape, X_valid.shape(torch.Size([100, 5]), torch.Size([10000, 5]))Y_train, Y_valid = Y_hat[:100], Y_hat[100:]
Y_train.shape, Y_valid.shape(torch.Size([100, 3]), torch.Size([10000, 3]))delete raw dataset¶
del X
del Y
del Y_hatModel and layers¶
layers¶
class Layer:
is_trainable: bool = False
passdense or full conect layer¶
class Dense(Layer):
def __init__(self, units: int):
self.units = units
self.is_trainable = True
def set_params(self, w: torch.Tensor, b: torch.Tensor) -> None:
self.w.copy_(w.T.detach().clone())
self.b.copy_(b.detach().clone())
def construct(self, x: torch.Tensor) -> torch.Tensor:
"""
Initialize the parameters
self.w := tensor (n_features, units).
self.b := tensor (units).
Args:
x: input tensor of shape (m_samples, n_features).
Return:
z: out tensor of shape (m_samples, units).
"""
n_features = x.shape[-1]
self.w = torch.randn(n_features, self.units, device=device)
self.b = torch.randn(self.units, device=device)
return self.forward(x)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Compute weighted sum Z = XW+b.
Args:
x: input tensor of shape (m_samples, n_features).
Return:
z: out tensor of shape (m_samples, units).
"""
return torch.matmul(x, self.w) + self.b
def __forward__(self, x: torch.Tensor) -> torch.Tensor:
"""Forward propagation for training step."""
self.input = x.clone()
return self.forward(x)
def backward(self, delta, lr: float) -> torch.Tensor:
# bias der and update
self.b -= lr * torch.sum(delta, axis=0)
# weight derivative (update weight after compute input der)
w_der = torch.matmul(self.input.T, delta)
# input derivative
delta = torch.matmul(delta, self.w.T)
# weight update
self.w -= lr * w_der
return deltaactivation functions¶
ReLU¶
class Relu(Layer):
def forward(self, z: torch.Tensor) -> torch.Tensor:
#return torch.relu(z)
return torch.max(z, torch.zeros_like(z))
def __forward__(self, z: torch.Tensor) -> torch.Tensor:
self.a = self.forward(z)
return self.a
def construct(self, z: torch.Tensor) -> torch.Tensor:
return self.forward(z)
def backward(self, delta, lr: float):
return delta * (1 * (self.a > 0))Sigmoid¶
class Sigmoid(Layer):
def forward(self, z: torch.Tensor) -> torch.Tensor:
#return torch.sigmoid(z)
return 1 / (1 + torch.exp(-z))
def __forward__(self, z: torch.Tensor) -> torch.Tensor:
self.a = self.forward(z)
return self.a
def construct(self, z: torch.Tensor) -> torch.Tensor:
return self.forward(z)
def backward(self, delta, lr: float):
return delta * (self.a * (1 - self.a))Tanh¶
class Tanh(Layer):
def forward(self, z: torch.Tensor) -> torch.Tensor:
#return torch.tanh(z)
exp = torch.exp(-2 * z)
return (1 - exp) / (1 + exp)
def __forward__(self, z: torch.Tensor) -> torch.Tensor:
self.a = self.forward(z)
return self.a
def construct(self, z: torch.Tensor) -> torch.Tensor:
return self.forward(z)
def backward(self, delta, lr: float):
return delta * (1 - self.a**2)Softmax¶
class Softmax(Layer):
def forward(self, z: torch.Tensor) -> torch.Tensor:
exp = torch.exp(z - torch.max(z, dim=1, keepdims=True)[0])
return exp / exp.sum(1, keepdims=True)
def __forward__(self, z: torch.Tensor) -> torch.Tensor:
self.a = self.forward(z)
return self.a
def construct(self, z: torch.Tensor) -> torch.Tensor:
return self.forward(z)
def backward(self, delta, lr: float):
return self.a * (delta - (delta * self.a).sum(axis=1, keepdims=True))input layer¶
class InputLayer(Layer):
def __init__(self, n_input_features: int):
self.m = 10
self.n = n_input_features
def construct(self) -> torch.Tensor:
return torch.randn(self.m, self.n, device=device)loss function¶
class Losses:
passMSE¶
class MSE(Losses):
def loss(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> float:
return ((y_pred - y_true)**2).mean().item()
def __call__(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> float:
return self.loss(y_pred, y_true)
def backward(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> torch.Tensor:
return 2 * (y_pred - y_true) / y_true.numel()scratch model¶
class Model:
def __init__(self, layers: list[Layer], loss_f: Losses = None):
self.layers = layers[1:] # do not save the input layer
self.loss_f = MSE() if loss_f is None else loss_f
# initialize all parameters
out = layers[0].construct()
for layer in self.layers:
out = layer.construct(out)
def copy_parameters(self, parameters) -> None:
params = list(parameters())
for layer in self.layers:
if layer.is_trainable:
layer.set_params(params.pop(0), params.pop(0))
def predict(self, x: torch.Tensor) -> torch.Tensor:
"""
Forward propagation.
Args:
x: tensor of shape (m_samples, n_input_features).
Return:
y_pred: tensor of shape (m_samples, n_out_features).
"""
out = x
for layer in self.layers:
out = layer.forward(out)
return out
def __forward__(self, x: torch.Tensor) -> torch.Tensor:
out = x
for layer in self.layers:
out = layer.__forward__(out)
return out
def evaluate(self, x: torch.Tensor, y: torch.Tensor) -> float:
"""
Evaluate the model between input x and target y.
Args:
x: tensor (m_samples, n_input_features).
y: target tensor (m_samples, n_out_features).
Return:
loss: error between y_pred and target y.
"""
y_pred = self.predict(x)
return self.loss_f(y_pred, y)
def update(self, y_pred: torch.Tensor, y_true: torch.Tensor, lr: float) -> None:
delta = self.loss_f.backward(y_pred, y_true)
for layer in reversed(self.layers):
delta = layer.backward(delta, lr)
def fit(self, x_train: torch.Tensor, y_train: torch.Tensor,
epochs: int, lr: float, batch_size: int,
x_valid: torch.Tensor, y_valid: torch.Tensor):
for epoch in range(epochs):
loss_t = [] # train loss
for batch in range(0, len(y_train), batch_size):
end_batch = batch + batch_size
y_pred = self.__forward__(x_train[batch:end_batch])
loss_t.append(self.loss_f(y_pred, y_train[batch:end_batch]))
self.update(y_pred, y_train[batch:end_batch], lr)
loss_t = sum(loss_t) / len(loss_t)
loss_v = self.evaluate(x_valid, y_valid) # valid loss
print('Epoch: {} - L: {:.4f} - L_v {:.4f}'.format(epoch, loss_t, loss_v))Torch sequential¶
class TorchSequential(nn.Module):
def __init__(self, layers: list[nn.Module], loss_fn=None):
super(TorchSequential, self).__init__()
self.layers = nn.ModuleList(layers)
for layer in self.layers:
layer.to(device)
self.loss_fn = loss_fn if loss_fn is not None else nn.MSELoss()
self.eval()
def forward(self, x):
out = x.clone()
for l in self.layers:
out = l(out)
return out
def evaluate(self, x, y):
self.eval()
with torch.no_grad():
y_pred = self(x)
return self.loss_fn(y_pred, y).item()
def fit(self, x: torch.Tensor, y: torch.Tensor,
epochs: int, lr: float, batch_size: int,
x_valid: torch.Tensor, y_valid: torch.Tensor):
optimizer = torch.optim.SGD(self.parameters(), lr=lr, momentum=0.0)
for epoch in range(epochs):
loss_t = []
for batch in range(0, len(y), batch_size):
end_batch = batch + batch_size
optimizer.zero_grad()
y_pred = self(x[batch:end_batch])
loss = self.loss_fn(y_pred, y[batch:end_batch])
loss_t.append(loss.item())
loss.backward()
optimizer.step()
loss_t = sum(loss_t) / len(loss_t)
loss_v = self.evaluate(x_valid, y_valid)
print('Epoch: {} - L: {:.4f} - L_v {:.4f}'.format(epoch, loss_t, loss_v))torch_model = TorchSequential([
nn.Linear(N, 32), nn.Tanh(),
nn.Linear(32, 32), nn.Sigmoid(),
nn.Linear(32, 32), nn.ReLU(),
nn.Linear(32, CLASSES), nn.Softmax(dim=1)
])Scratch vs Sequential¶
scratch model¶
model = Model([
InputLayer(N),
Dense(32), Tanh(),
Dense(32), Sigmoid(),
Dense(32), Relu(),
Dense(CLASSES), Softmax()
])evals¶
import MAPE modified¶
# This cell imports torch_mape
# if you are running this notebook locally
# or from Google Colab.
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
try:
from tools.torch_metrics import torch_mape as mape
print('mape imported locally.')
except ModuleNotFoundError:
import subprocess
repo_url = 'https://raw.githubusercontent.com/PilotLeoYan/inside-deep-learning/main/content/tools/torch_metrics.py'
local_file = 'torch_metrics.py'
subprocess.run(['wget', repo_url, '-O', local_file], check=True)
try:
from torch_metrics import torch_mape as mape # type: ignore
print('mape imported from GitHub.')
except Exception as e:
print(e)mape imported locally.
predict¶
mape(
model.predict(X_valid),
torch_model(X_valid)
)125.42750891787074copy parameters¶
model.copy_parameters(torch_model.parameters)predict after copy parameters¶
mape(
model.predict(X_valid),
torch_model(X_valid)
)5.273548430481444e-15loss¶
mape(
model.evaluate(X_valid, Y_valid),
torch_model.evaluate(X_valid, Y_valid)
)0.0train¶
LR: float = 0.08
EPOCHS: int = 32
BATCH_SIZE: int = len(Y_train) // 3torch_model.fit(
X_train, Y_train.double(),
EPOCHS, LR, BATCH_SIZE,
X_valid, Y_valid.double()
)Epoch: 0 - L: 0.2156 - L_v 0.2236
Epoch: 1 - L: 0.2140 - L_v 0.2243
Epoch: 2 - L: 0.2129 - L_v 0.2250
Epoch: 3 - L: 0.2120 - L_v 0.2258
Epoch: 4 - L: 0.2113 - L_v 0.2265
Epoch: 5 - L: 0.2107 - L_v 0.2271
Epoch: 6 - L: 0.2102 - L_v 0.2277
Epoch: 7 - L: 0.2098 - L_v 0.2282
Epoch: 8 - L: 0.2095 - L_v 0.2287
Epoch: 9 - L: 0.2091 - L_v 0.2291
Epoch: 10 - L: 0.2088 - L_v 0.2294
Epoch: 11 - L: 0.2086 - L_v 0.2296
Epoch: 12 - L: 0.2083 - L_v 0.2298
Epoch: 13 - L: 0.2080 - L_v 0.2299
Epoch: 14 - L: 0.2078 - L_v 0.2300
Epoch: 15 - L: 0.2075 - L_v 0.2300
Epoch: 16 - L: 0.2072 - L_v 0.2300
Epoch: 17 - L: 0.2069 - L_v 0.2299
Epoch: 18 - L: 0.2066 - L_v 0.2298
Epoch: 19 - L: 0.2064 - L_v 0.2297
Epoch: 20 - L: 0.2061 - L_v 0.2296
Epoch: 21 - L: 0.2058 - L_v 0.2294
Epoch: 22 - L: 0.2055 - L_v 0.2293
Epoch: 23 - L: 0.2052 - L_v 0.2291
Epoch: 24 - L: 0.2048 - L_v 0.2289
Epoch: 25 - L: 0.2045 - L_v 0.2286
Epoch: 26 - L: 0.2042 - L_v 0.2284
Epoch: 27 - L: 0.2038 - L_v 0.2282
Epoch: 28 - L: 0.2035 - L_v 0.2279
Epoch: 29 - L: 0.2031 - L_v 0.2276
Epoch: 30 - L: 0.2027 - L_v 0.2274
Epoch: 31 - L: 0.2024 - L_v 0.2271
model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH_SIZE,
X_valid, Y_valid
)Epoch: 0 - L: 0.2156 - L_v 0.2236
Epoch: 1 - L: 0.2140 - L_v 0.2243
Epoch: 2 - L: 0.2129 - L_v 0.2250
Epoch: 3 - L: 0.2120 - L_v 0.2258
Epoch: 4 - L: 0.2113 - L_v 0.2265
Epoch: 5 - L: 0.2107 - L_v 0.2271
Epoch: 6 - L: 0.2102 - L_v 0.2277
Epoch: 7 - L: 0.2098 - L_v 0.2282
Epoch: 8 - L: 0.2095 - L_v 0.2287
Epoch: 9 - L: 0.2091 - L_v 0.2291
Epoch: 10 - L: 0.2088 - L_v 0.2294
Epoch: 11 - L: 0.2086 - L_v 0.2296
Epoch: 12 - L: 0.2083 - L_v 0.2298
Epoch: 13 - L: 0.2080 - L_v 0.2299
Epoch: 14 - L: 0.2078 - L_v 0.2300
Epoch: 15 - L: 0.2075 - L_v 0.2300
Epoch: 16 - L: 0.2072 - L_v 0.2300
Epoch: 17 - L: 0.2069 - L_v 0.2299
Epoch: 18 - L: 0.2066 - L_v 0.2298
Epoch: 19 - L: 0.2064 - L_v 0.2297
Epoch: 20 - L: 0.2061 - L_v 0.2296
Epoch: 21 - L: 0.2058 - L_v 0.2294
Epoch: 22 - L: 0.2055 - L_v 0.2293
Epoch: 23 - L: 0.2052 - L_v 0.2291
Epoch: 24 - L: 0.2048 - L_v 0.2289
Epoch: 25 - L: 0.2045 - L_v 0.2286
Epoch: 26 - L: 0.2042 - L_v 0.2284
Epoch: 27 - L: 0.2038 - L_v 0.2282
Epoch: 28 - L: 0.2035 - L_v 0.2279
Epoch: 29 - L: 0.2031 - L_v 0.2276
Epoch: 30 - L: 0.2027 - L_v 0.2274
Epoch: 31 - L: 0.2024 - L_v 0.2271
predict after train¶
mape(
model.predict(X_valid),
torch_model(X_valid)
)7.151104781913563e-15bias¶
for k in range(len(model.layers)):
if not model.layers[k].is_trainable:
continue
print(f'layer #{k}')
print(mape(model.layers[k].b, torch_model.layers[k].bias))layer #0
1.7679967654945007e-15
layer #2
3.89758312433065e-15
layer #4
1.809379053016804e-14
layer #6
5.780032846384725e-15
weight¶
for k in range(len(model.layers)):
if not model.layers[k].is_trainable:
continue
print(f'layer #{k}')
print(mape(model.layers[k].w, torch_model.layers[k].weight.T))layer #0
2.2494070184096167e-15
layer #2
4.7606392179558714e-15
layer #4
8.212124707703948e-15
layer #6
1.6346739211448424e-14