Now we are going to increase the complexity, instead of the perceptron having a single output, it will now have multiple outputs. The word “multivariable” usually means that the perceptron receives multiple inputs, but here we will use it to describe that the perceptron has multiple outputs.

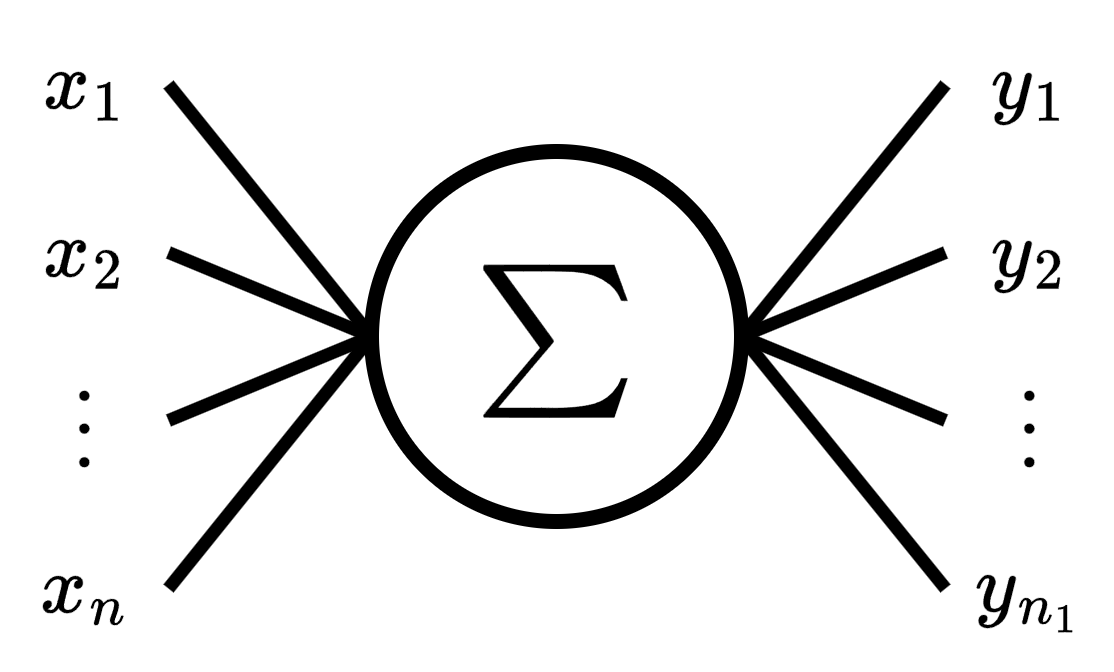
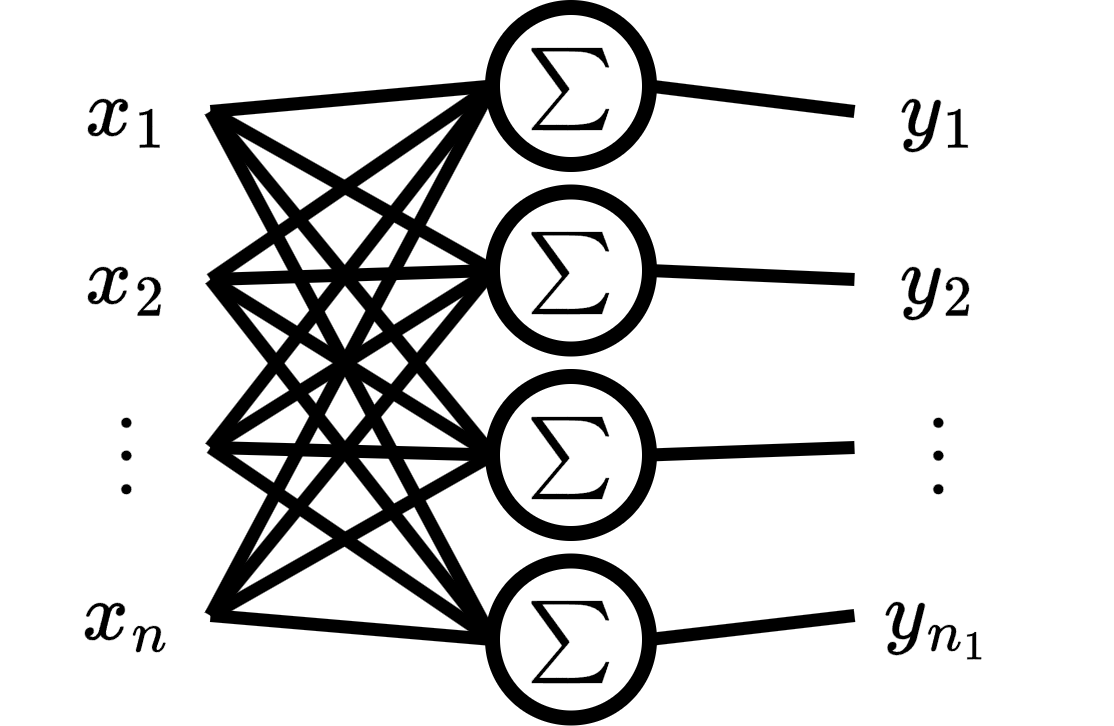
We can think of the multivariate perceptron as a layer of multiple simple perceptrons, and that each perceptron output corresponds to an output feature.
Purpose of this Notebook:
The purposes of this notebook are:
Create a dataset for multivariate linear regression task
Create our own Multivariate Perceptron class from scratch
Calculate the gradient descent from scratch
Train our Multivariate Perceptron
Compare our Perceptron to the one prebuilt by PyTorch
[Extra] Calculate the gradient descent by other way
import torch
from torch import nn
from platform import python_version
python_version(), torch.__version__('3.12.12', '2.9.0+cu128')device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
device'cpu'torch.set_default_dtype(torch.float64)def add_to_class(Class):
"""Register functions as methods in created class."""
def wrapper(obj): setattr(Class, obj.__name__, obj)
return wrapperDataset¶
create dataset¶
where is the number of output features.
from sklearn.datasets import make_regression
import random
M: int = 10_100 # number of samples
N: int = 6 # number of input features
NO: int = 3 # number of output features
X, Y = make_regression(
n_samples=M,
n_features=N,
n_targets=NO,
n_informative=N - 1,
bias=random.random(),
noise=1
)
print(X.shape)
print(Y.shape)(10100, 6)
(10100, 3)
split dataset¶
X_train = torch.tensor(X[:100], device=device)
Y_train = torch.tensor(Y[:100], device=device)
X_train.shape, Y_train.shape(torch.Size([100, 6]), torch.Size([100, 3]))X_valid = torch.tensor(X[100:], device=device)
Y_valid = torch.tensor(Y[100:], device=device)
X_valid.shape, Y_valid.shape(torch.Size([10000, 6]), torch.Size([10000, 3]))delete raw dataset¶
del X
del YScratch model¶
weights and bias¶
trainable parameters
class LinearRegression:
def __init__(self, n_features: int, out_features: int):
self.w = torch.randn(n_features, out_features, device=device)
self.b = torch.randn(out_features, device=device)
def copy_params(self, torch_layer: torch.nn.modules.linear.Linear):
"""
Copy the parameters from a module.linear to this model.
Args:
torch_layer: Pytorch module from which to copy the parameters.
"""
self.b.copy_(torch_layer.bias.detach().clone())
self.w.copy_(torch_layer.weight.T.detach().clone())weighted sum¶
where
for all and .
@add_to_class(LinearRegression)
def predict(self, x: torch.Tensor) -> torch.Tensor:
"""
Predict the output for input x
Args:
x: Input tensor of shape (n_samples, n_features).
Returns:
y_pred: Predicted output tensor of shape (n_samples, out_features).
"""
return torch.matmul(x, self.w) + self.bMSE¶
Mean Squared Error
Vectorized form
where is element-wise power or also .
Note: is called element-wise product or also Hadamard product.
@add_to_class(LinearRegression)
def mse_loss(self, y_true: torch.Tensor, y_pred: torch.Tensor):
"""
MSE loss function between target y_true and y_pred.
Args:
y_true: Target tensor of shape (n_samples, out_features).
y_pred: Predicted tensor of shape (n_samples, out_features).
Returns:
loss: MSE loss between predictions and true values.
"""
return ((y_pred - y_true)**2).mean().item()
@add_to_class(LinearRegression)
def evaluate(self, x: torch.Tensor, y_true: torch.Tensor):
"""
Evaluate the model on input x and target y_true using MSE.
Args:
x: Input tensor of shape (n_samples, n_features).
y_true: Target tensor of shape (n_samples, out_features).
Returns:
loss: MSE loss between predictions and true values.
"""
y_pred = self.predict(x)
return self.mse_loss(y_true, y_pred)compute gradients¶
There are two ways to compute gradients
Computing each derivative individually and then joining them using the Einstein summation.
Computing an initial derivative and passing it backwards as an argument.
The most common way is to use method 2 because it is easier to visualize and is more optimal. While method 1 needs more computing. We prefer method 2, but we will also use method 1 just for comparison.
MSE derivative¶
for all and .
then
therefore
weighted sum derivative¶
respect to bias¶
for all .
then
therefore
where .
respect to weight¶
for all and .
then
therefore
gradients¶
and
Parameters update¶
@add_to_class(LinearRegression)
def update(self, x: torch.Tensor, y_true: torch.Tensor, y_pred: torch.Tensor, lr: float):
"""
Update the model parameters.
Args:
x: Input tensor of shape (n_samples, n_features).
y_true: Target tensor of shape (n_samples, n_features).
y_pred: Predicted output tensor of shape (n_samples, n_features).
lr: Learning rate.
"""
delta = 2 * (y_pred - y_true) / y_true.numel()
self.b -= lr * delta.sum(axis=0)
self.w -= lr * torch.matmul(x.T, delta)fit (train)¶
@add_to_class(LinearRegression)
def fit(self, x_train: torch.Tensor, y_train: torch.Tensor,
epochs: int, lr: float, batch_size: int,
x_valid: torch.Tensor, y_valid: torch.Tensor):
"""
Fit the model using gradient descent.
Args:
x_train: Input tensor of shape (n_samples, n_features).
y_train: Target tensor of shape (n_samples,).
epochs: Number of epochs to fit.
lr: learning rate.
batch_size: Int number of batch.
x_valid: Input tensor of shape (n_valid_samples, n_features).
y_valid: Target tensor of shape (n_valid_samples,)
"""
for epoch in range(epochs):
loss = []
for batch in range(0, len(y_train), batch_size):
end_batch = batch + batch_size
y_pred = self.predict(x_train[batch:end_batch])
loss.append(self.mse_loss(
y_train[batch:end_batch],
y_pred
))
self.update(
x_train[batch:end_batch],
y_train[batch:end_batch],
y_pred,
lr
)
loss = round(sum(loss) / len(loss), 4)
loss_v = round(self.evaluate(x_valid, y_valid), 4)
print(f'epoch: {epoch} - MSE: {loss} - MSE_v: {loss_v}')Scratch vs Torch.nn¶
Torch.nn model¶
class TorchLinearRegression(nn.Module):
def __init__(self, n_features, n_out_features):
super(TorchLinearRegression, self).__init__()
self.layer = nn.Linear(n_features, n_out_features, device=device)
self.loss = nn.MSELoss()
def forward(self, x):
return self.layer(x)
def evaluate(self, x, y):
self.eval()
with torch.no_grad():
y_pred = self.forward(x)
return self.loss(y_pred, y).item()
def fit(self, x, y, epochs, lr, batch_size, x_valid, y_valid):
optimizer = torch.optim.SGD(self.parameters(), lr=lr)
for epoch in range(epochs):
loss_t = []
for batch in range(0, len(y), batch_size):
end_batch = batch + batch_size
y_pred = self.forward(x[batch:end_batch])
loss = self.loss(y_pred, y[batch:end_batch])
loss_t.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_t = round(sum(loss_t) / len(loss_t), 4)
loss_v = round(self.evaluate(x_valid, y_valid), 4)
print(f'epoch: {epoch} - MSE: {loss_t} - MSE_v: {loss_v}')torch_model = TorchLinearRegression(N, NO)scratch model¶
model = LinearRegression(N, NO)evals¶
import MAPE modified¶
# This cell imports torch_mape
# if you are running this notebook locally
# or from Google Colab.
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
try:
from tools.torch_metrics import torch_mape as mape
print('mape imported locally.')
except ModuleNotFoundError:
import subprocess
repo_url = 'https://raw.githubusercontent.com/PilotLeoYan/inside-deep-learning/main/content/tools/torch_metrics.py'
local_file = 'torch_metrics.py'
subprocess.run(['wget', repo_url, '-O', local_file], check=True)
try:
from torch_metrics import torch_mape as mape # type: ignore
print('mape imported from GitHub.')
except Exception as e:
print(e)mape imported locally.
predict¶
mape(
model.predict(X_valid),
torch_model.forward(X_valid)
)2012.6907730318287copy parameters¶
model.copy_params(torch_model.layer)
parameters = (model.b.clone(), model.w.clone())predict after copy parameters¶
mape(
model.predict(X_valid),
torch_model.forward(X_valid)
)0.0loss¶
mape(
model.evaluate(X_valid, Y_valid),
torch_model.evaluate(X_valid, Y_valid)
)0.0train¶
LR = 0.01 # learning rate
EPOCHS = 16 # number of epochs
BATCH = len(X_train) // 3 # batch sizetorch_model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH,
X_valid, Y_valid
)epoch: 0 - MSE: 17391.688 - MSE_v: 20044.5903
epoch: 1 - MSE: 16412.7443 - MSE_v: 19176.1657
epoch: 2 - MSE: 15515.7891 - MSE_v: 18354.4923
epoch: 3 - MSE: 14691.1138 - MSE_v: 17575.8712
epoch: 4 - MSE: 13930.3666 - MSE_v: 16837.0262
epoch: 5 - MSE: 13226.3524 - MSE_v: 16135.0464
epoch: 6 - MSE: 12572.8618 - MSE_v: 15467.3357
epoch: 7 - MSE: 11964.5268 - MSE_v: 14831.5704
epoch: 8 - MSE: 11396.6974 - MSE_v: 14225.6629
epoch: 9 - MSE: 10865.3368 - MSE_v: 13647.7305
epoch: 10 - MSE: 10366.9328 - MSE_v: 13096.0693
epoch: 11 - MSE: 9898.4219 - MSE_v: 12569.1311
epoch: 12 - MSE: 9457.1245 - MSE_v: 12065.5042
epoch: 13 - MSE: 9040.6908 - MSE_v: 11583.8965
epoch: 14 - MSE: 8647.0537 - MSE_v: 11123.1215
epoch: 15 - MSE: 8274.389 - MSE_v: 10682.086
model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH,
X_valid, Y_valid
)epoch: 0 - MSE: 17391.688 - MSE_v: 20044.5903
epoch: 1 - MSE: 16412.7443 - MSE_v: 19176.1657
epoch: 2 - MSE: 15515.7891 - MSE_v: 18354.4923
epoch: 3 - MSE: 14691.1138 - MSE_v: 17575.8712
epoch: 4 - MSE: 13930.3666 - MSE_v: 16837.0262
epoch: 5 - MSE: 13226.3524 - MSE_v: 16135.0464
epoch: 6 - MSE: 12572.8618 - MSE_v: 15467.3357
epoch: 7 - MSE: 11964.5268 - MSE_v: 14831.5704
epoch: 8 - MSE: 11396.6974 - MSE_v: 14225.6629
epoch: 9 - MSE: 10865.3368 - MSE_v: 13647.7305
epoch: 10 - MSE: 10366.9328 - MSE_v: 13096.0693
epoch: 11 - MSE: 9898.4219 - MSE_v: 12569.1311
epoch: 12 - MSE: 9457.1245 - MSE_v: 12065.5042
epoch: 13 - MSE: 9040.6908 - MSE_v: 11583.8965
epoch: 14 - MSE: 8647.0537 - MSE_v: 11123.1215
epoch: 15 - MSE: 8274.389 - MSE_v: 10682.086
predict after training¶
mape(
model.predict(X_valid),
torch_model.forward(X_valid)
)6.41623922729972e-14weight¶
mape(
model.w.clone(),
torch_model.layer.weight.detach().T
)1.1964026011221981e-14bias¶
mape(
model.b.clone(),
torch_model.layer.bias.detach()
)9.992714588903911e-14Compute gradient with einsum¶
where their shapes are
Note: check has four axes. This is an example because this method requires more computing.
weighted sum derivative respect to bias
for all and
weighted sum derivative respect to weight
for all ,
and
.
Vectorized form
where is Kronecker product.
therefore using Einstein summation
and
Model¶
class EinsumLinearRegression(LinearRegression):
def update(self, x: torch.Tensor, y_true: torch.Tensor, y_pred: torch.Tensor, lr: float):
"""
Update the model parameters.
Args:
x: Input tensor of shape (n_samples, n_features).
y_true: Target tensor of shape (n_samples, n_features).
y_pred: Predicted output tensor of shape (n_samples, n_features).
lr: Learning rate.
"""
delta = 2 * (y_pred - y_true) / y_true.numel()
# d L / d b
self.b -= lr * delta.sum(axis=0)
# d L / d W
identity = torch.eye(y_true.shape[-1], device=device)
w_der = torch.kron(
x.unsqueeze(1).unsqueeze(3),
identity.unsqueeze(0).unsqueeze(2)
)
self.w -= lr * torch.einsum('pq,pqij->ij', delta, w_der)einsum_model = EinsumLinearRegression(N, NO)
einsum_model.b.copy_(parameters[0])
einsum_model.w.copy_(parameters[1])tensor([[ 0.3878, -0.0049, 0.2929],
[ 0.1414, -0.0438, 0.0712],
[-0.3527, 0.3928, -0.0829],
[-0.3182, -0.0721, 0.0125],
[-0.3025, 0.3572, -0.1896],
[ 0.2709, -0.2265, 0.2992]])einsum_model.fit(
X_train, Y_train,
EPOCHS, LR, BATCH,
X_valid, Y_valid
)epoch: 0 - MSE: 17391.688 - MSE_v: 20044.5903
epoch: 1 - MSE: 16412.7443 - MSE_v: 19176.1657
epoch: 2 - MSE: 15515.7891 - MSE_v: 18354.4923
epoch: 3 - MSE: 14691.1138 - MSE_v: 17575.8712
epoch: 4 - MSE: 13930.3666 - MSE_v: 16837.0262
epoch: 5 - MSE: 13226.3524 - MSE_v: 16135.0464
epoch: 6 - MSE: 12572.8618 - MSE_v: 15467.3357
epoch: 7 - MSE: 11964.5268 - MSE_v: 14831.5704
epoch: 8 - MSE: 11396.6974 - MSE_v: 14225.6629
epoch: 9 - MSE: 10865.3368 - MSE_v: 13647.7305
epoch: 10 - MSE: 10366.9328 - MSE_v: 13096.0693
epoch: 11 - MSE: 9898.4219 - MSE_v: 12569.1311
epoch: 12 - MSE: 9457.1245 - MSE_v: 12065.5042
epoch: 13 - MSE: 9040.6908 - MSE_v: 11583.8965
epoch: 14 - MSE: 8647.0537 - MSE_v: 11123.1215
epoch: 15 - MSE: 8274.389 - MSE_v: 10682.086
mape(
einsum_model.w.clone(),
torch_model.layer.weight.detach().T
)1.133194750373222e-14mape(
einsum_model.b.clone(),
torch_model.layer.bias.detach()
)8.576651852262388e-14